In this notebook we will compare methods for creating new columns using conditional tests.
The first type of test is an if/else test, where we provide an outcome if a test returns TRUE and an outcome if a test returns FALSE.
The second test is a case_when test, which allows us to specify any number of individual test –> result relationships.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Load in data
We can use a data set which contains measures of linguistic features for a set of satirical (The Onion) and non-satirical (The New York Times) headlines.
dat <-read_csv('https://raw.githubusercontent.com/scskalicky/scskalicky.github.io/refs/heads/main/sample_dat/linguistic_features.csv')
Rows: 80 Columns: 19
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): headline, filename, condition
dbl (16): conditionNum, MLC, numContenWords, numWords, numFunctionWords, MRC...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
variables of interest
condition, this variable shows that headlines are in one of five conditions: atten, saturation, metaphor, negation, and control. The four conditions that are not the control condition are four different strategies for doing satire, but they are all nonetheless satirical headlines.
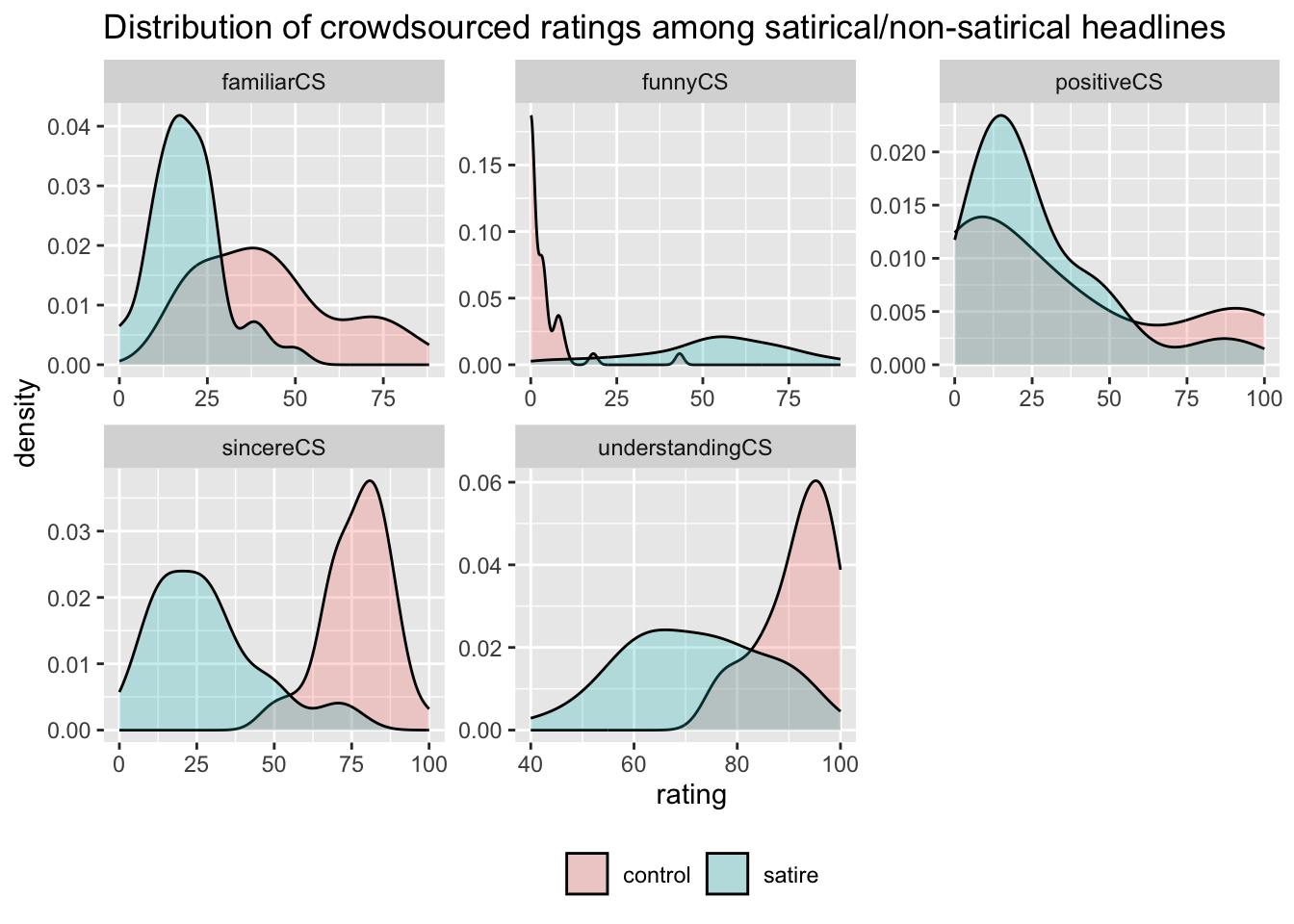
“CS” variables. There are five variables in the data that represent ratings of the headlines for familiarity, understanding, positive, sincerity, and funnyness. The variables all end in the string “CS” because they were gathered using crowdsourcing methods (in this case, from workers on the Amazon Mechanical Turk platform).
Let’s create a dataframe that has only these variables.
dat_smol <- dat %>%select(condition, ends_with("CS"))
What if we want to create a new column that contains a label showing whether a headline is simply satirical or non-satirical?
We know that we can create a new column using mutate(), so we just need to determine a new conditional test on the column that helps with this (i.e., condition).
Here we will use if_else to conduct a binary test.
Let’s first check to see how the function works. We first creat a conditional test, then the value that should be returned if the test is true, then the value for if the test is false. For example…
# if the condition column is 'atten', return a 1, otherwise return a 0if_else(dat$condition =='atten', 1, 0)
Notice that the function operates on the entire column and returns values the same length of the column. This is by design so that we can quickly vectorize over columns in our df. So if we want to create a new column called condition_big that contains the values satire or control, we could do this:
There is another way to do this, using case_when(). This function performs one conditional test and returns a value only if that test is true, otherwise it returns NA
For case_when(): the syntax uses what is called formula notation, and is in the form of case_when(condition ~ result). For example, if you wanted to turn all values of 'cat' into 'dog', you could use case_when(variable == 'cat' ~ 'dog'). The usefulness of case_when() is seen in that you can put multiple conditions and results inside a single case_when() function: case_when(variable == 'a' ~ 0, variable == 'b' ~ 1, and so on...).
Let’s use case_when() to complete the same operation as above, create a new column that has the value satire if condition is not equal to control, and otherwise has the value control
It works, but also fills NA for everything where the test did not return true.
dat_smol$condition_big
[1] NA NA "control" "control" "control" NA "control"
[8] "control" "control" NA NA NA NA NA
[15] NA NA NA "control" "control" "control" NA
[22] NA "control" NA "control" "control" NA NA
[29] NA "control" "control" "control" "control" "control" "control"
[36] "control" NA "control" NA NA "control" NA
[43] "control" NA "control" NA "control" "control" "control"
[50] "control" "control" "control" NA "control" NA NA
[57] NA "control" "control" "control" NA "control" NA
[64] NA NA "control" NA "control" NA NA
[71] "control" "control" NA NA "control" "control" NA
[78] NA NA NA
add a second case for when the condition is not control:
You can see that in this example, if_else was a more efficient and even elegant solution when compared to case_when(). However, what happens if we have three different outcomes we’d like to create? Then case_when() might start to be more useful. For example, among the four types of satire, two are different forms of exaggeration (saturation / attentuation) whereas the other two are negated or metaphor. let’s say we want to classify these into three categories:
satire-exaggerate, satire-met-neg, and control
We can write a case_when() call to handle this easily.
# remove the column so we can start freshdat_smol$condition_big <-NULL
In case it is useful, you can add a final argument to a case_when() call to set a default value to all other cases that don’t pass a test. It looks like this, and in this case has very similar functionality to if_else!
# the final TRUE sets the default condition, dat_smol <- dat_smol %>%mutate(condition_big =case_when(dat_smol$condition =='control'~'control', TRUE~'satire'))dat_smol$condition_big